项目介绍
本项目旨在通过分析泰坦尼克号乘客数据集,探索影响乘客生存的关键因素,并建立预测模型来预测乘客的生存概率。通过应用机器学习和数据分析技术,我们发现了一些有价值的见解,可以帮助我们更好地理解这场历史性灾难中的生存模式。

图1: 泰坦尼克号
数据预览
泰坦尼克号数据集包含了乘客的各种信息,如年龄、性别、票价、舱位等。以下是数据集的基本信息和统计摘要:
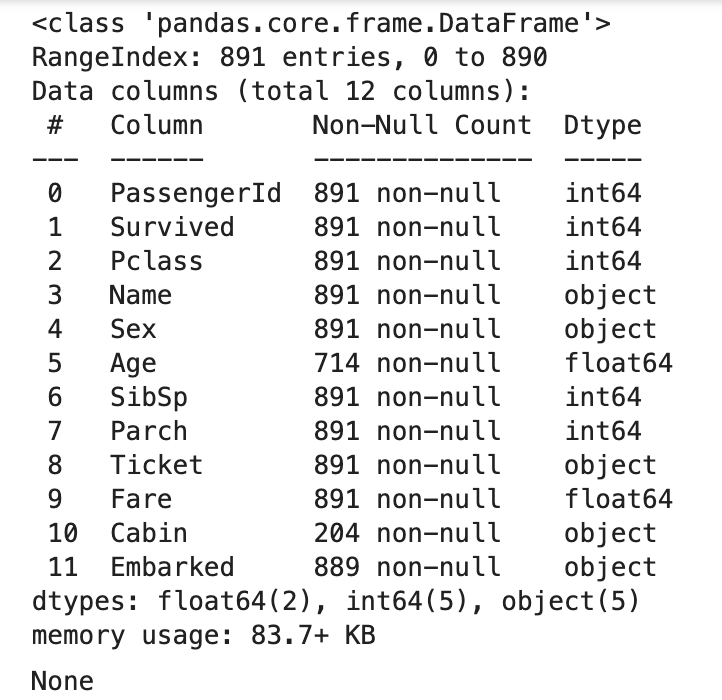
图2: 数据集基本信息
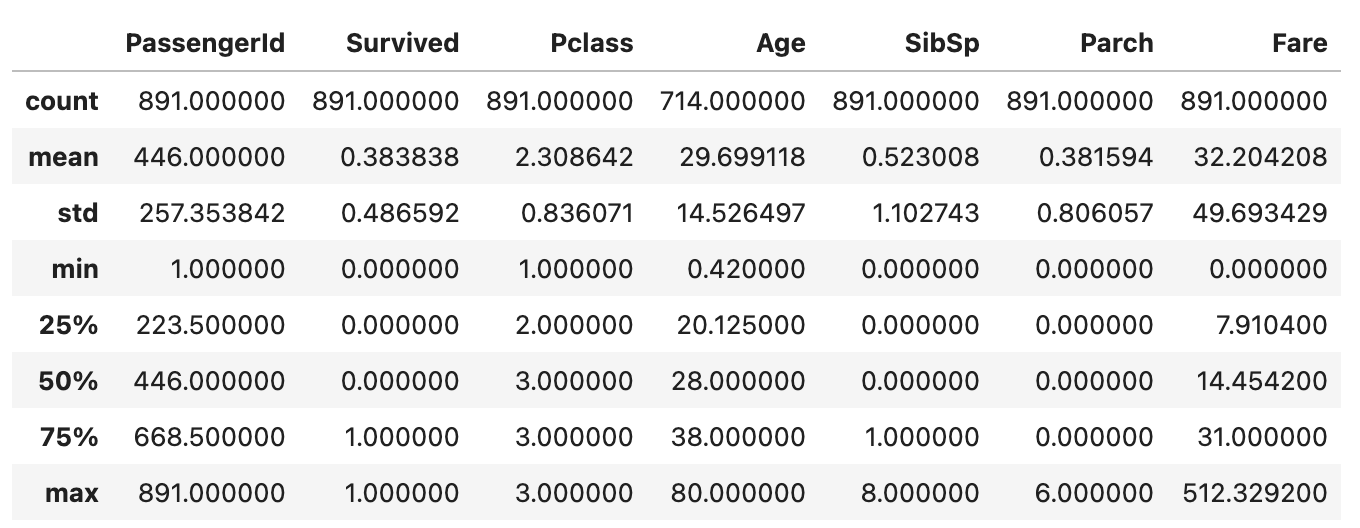
图3: 数据统计摘要
缺失值检查
在进行数据分析前,我们首先检查了数据集中的缺失值情况:
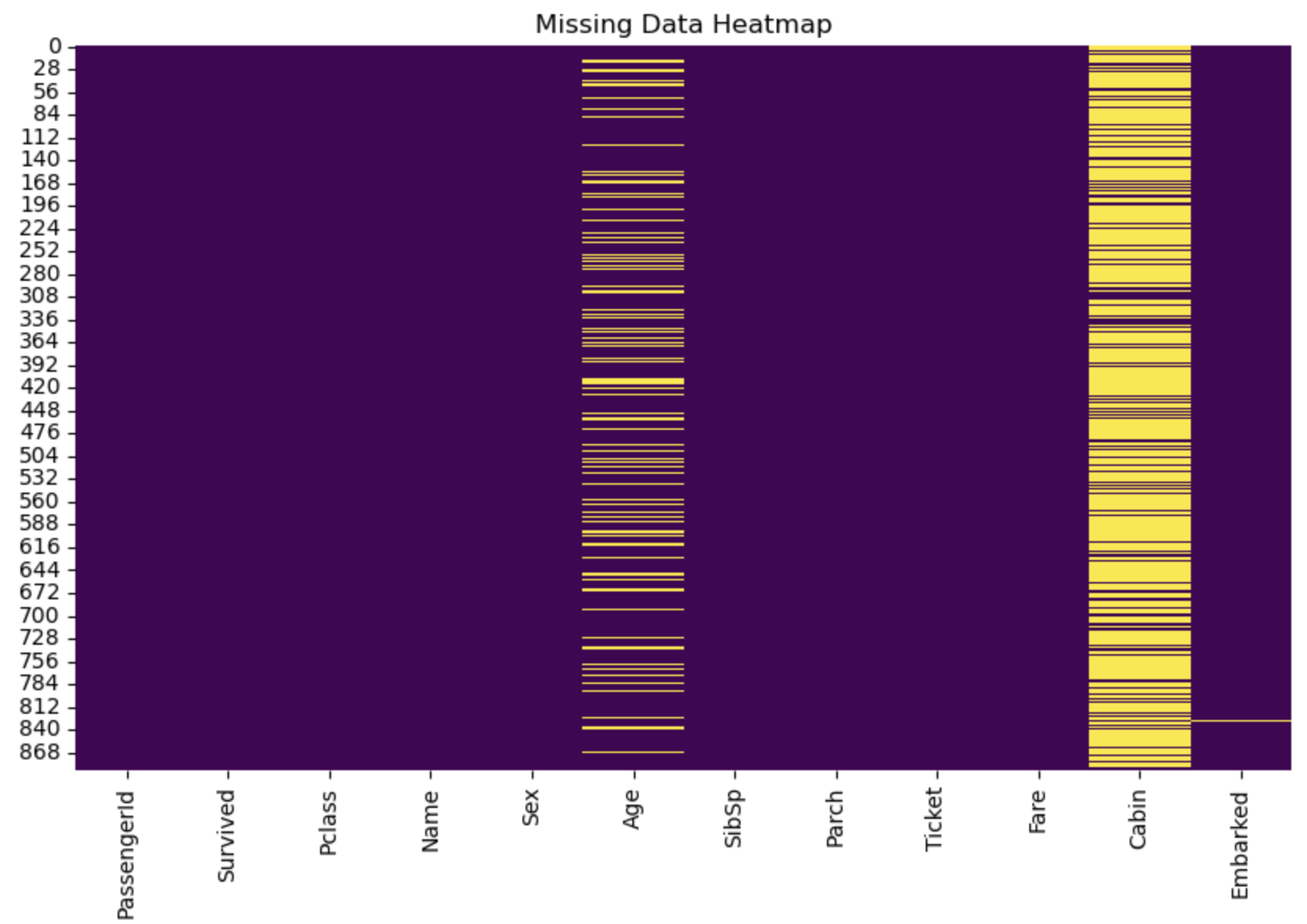
图4: 数据集缺失值热图
从热图中可以看出,主要的缺失值出现在Age(年龄)、Cabin(船舱)和Embarked(登船港口)这几个特征中。其中Cabin缺失值最多,Age有部分缺失,而Embarked只有少量缺失。
研究方法
我们采用了以下方法来分析泰坦尼克号数据:
- 数据收集与预处理
- 探索性数据分析
- 特征工程
- 随机森林分类模型
- 模型评估与结果可视化
数据加载与预览
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import numpy as np
# 加载数据
df = pd.read_csv("https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv")
# 数据预览
display(df.info())
display(df.describe())
数据清洗与预处理
# 数据可视化 - 缺失值检查
plt.figure(figsize=(10, 6))
sns.heatmap(df.isnull(), cbar=False, cmap='viridis')
plt.title("Missing Data Heatmap")
plt.savefig('missing_data.png', dpi=300)
plt.show()
# 数据清洗
df.drop(['Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
df['Age'] = df['Age'].fillna(df['Age'].median())
df['Embarked'] = df['Embarked'].fillna(df['Embarked'].mode()[0])
df['Fare'] = df['Fare'].fillna(df['Fare'].median())
df['Sex'] = df['Sex'].map({'male': 0, 'female': 1})
df = pd.get_dummies(df, columns=['Embarked'], drop_first=True)
# 特征工程 - 创建新特征
df['FamilySize'] = df['SibSp'] + df['Parch'] + 1
数据分析
在分析过程中,我们发现了以下关键模式:
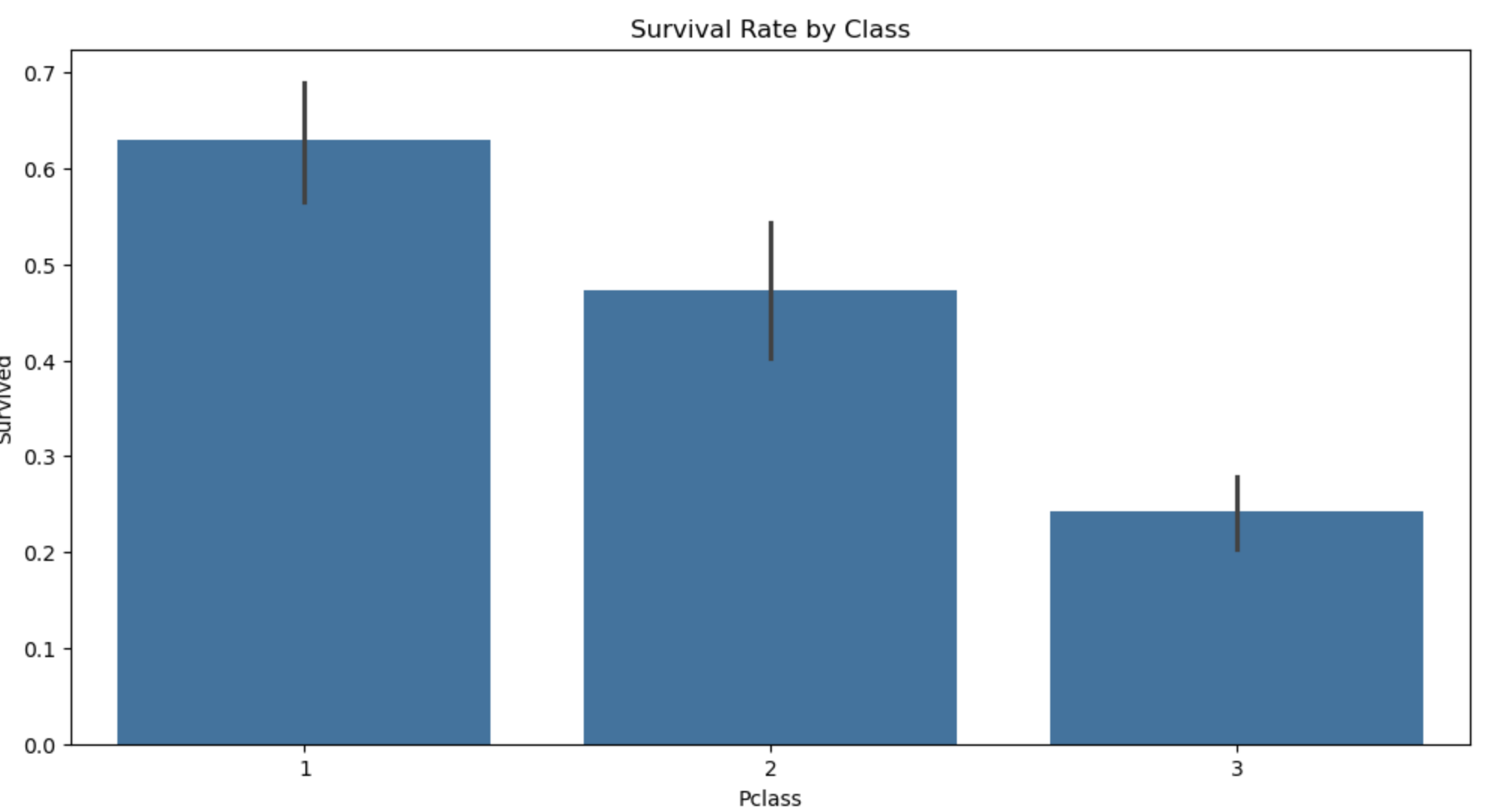
图6: 不同舱位的生存率
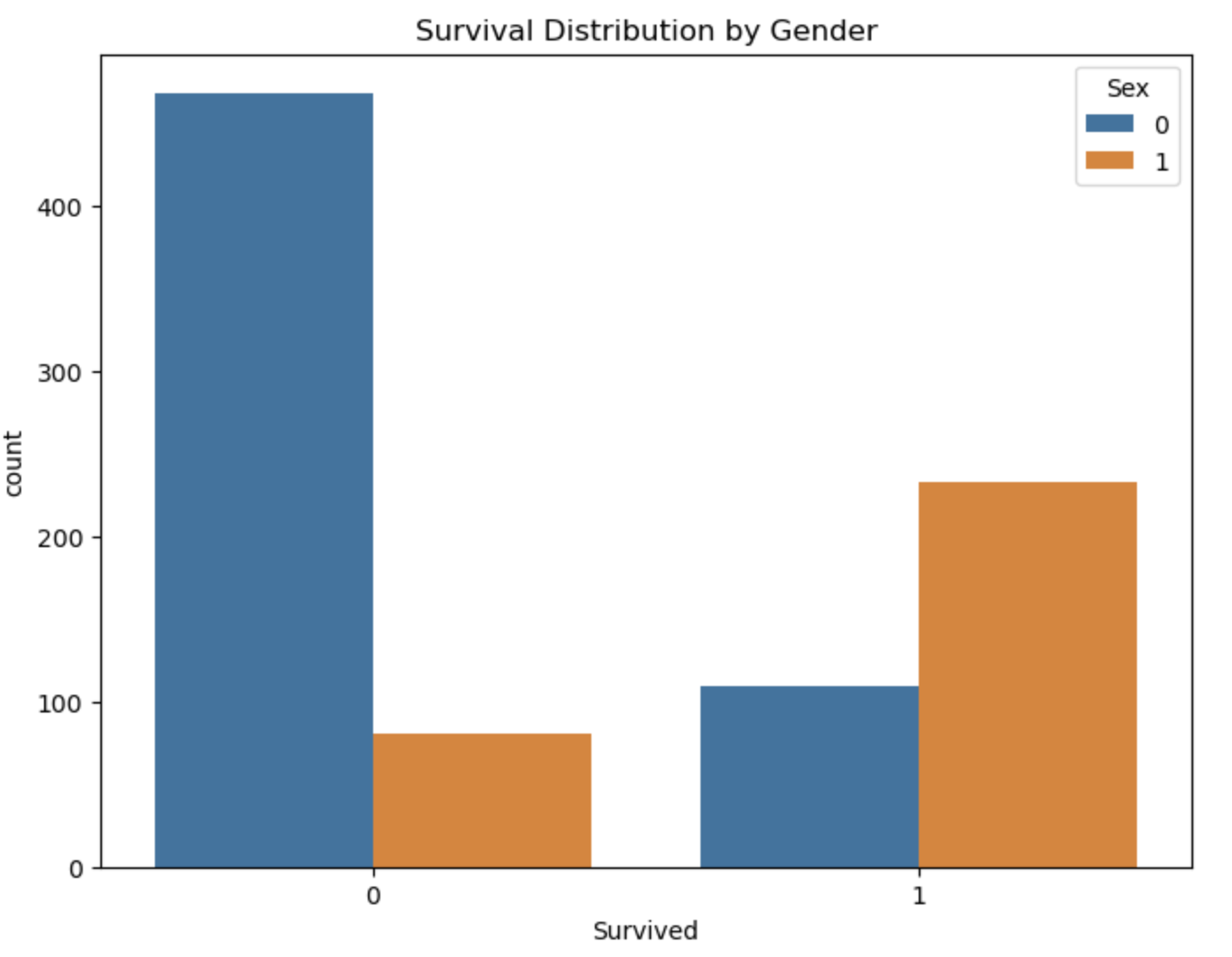
图7: 不同性别的生存率
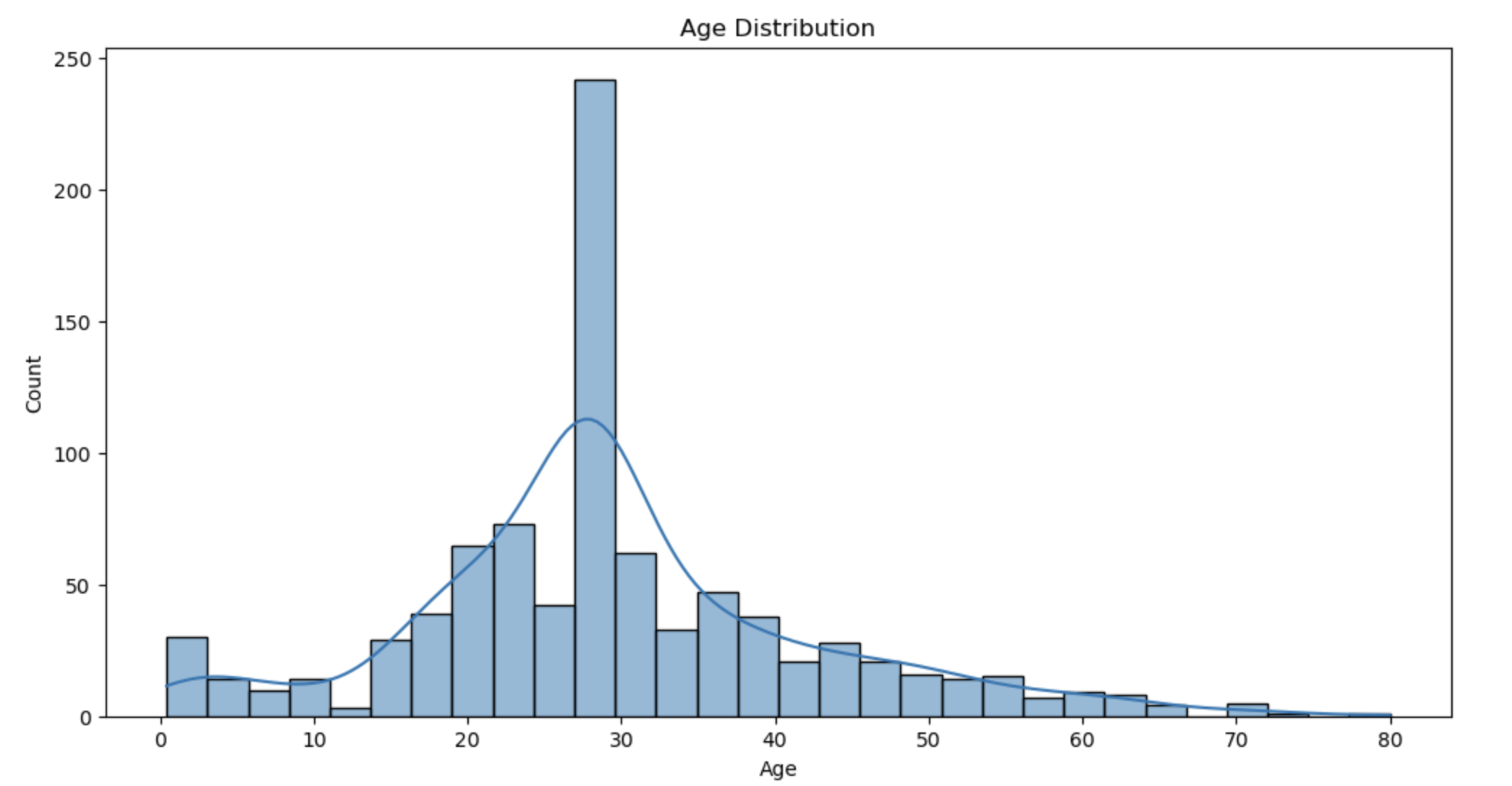
图8: 乘客年龄分布
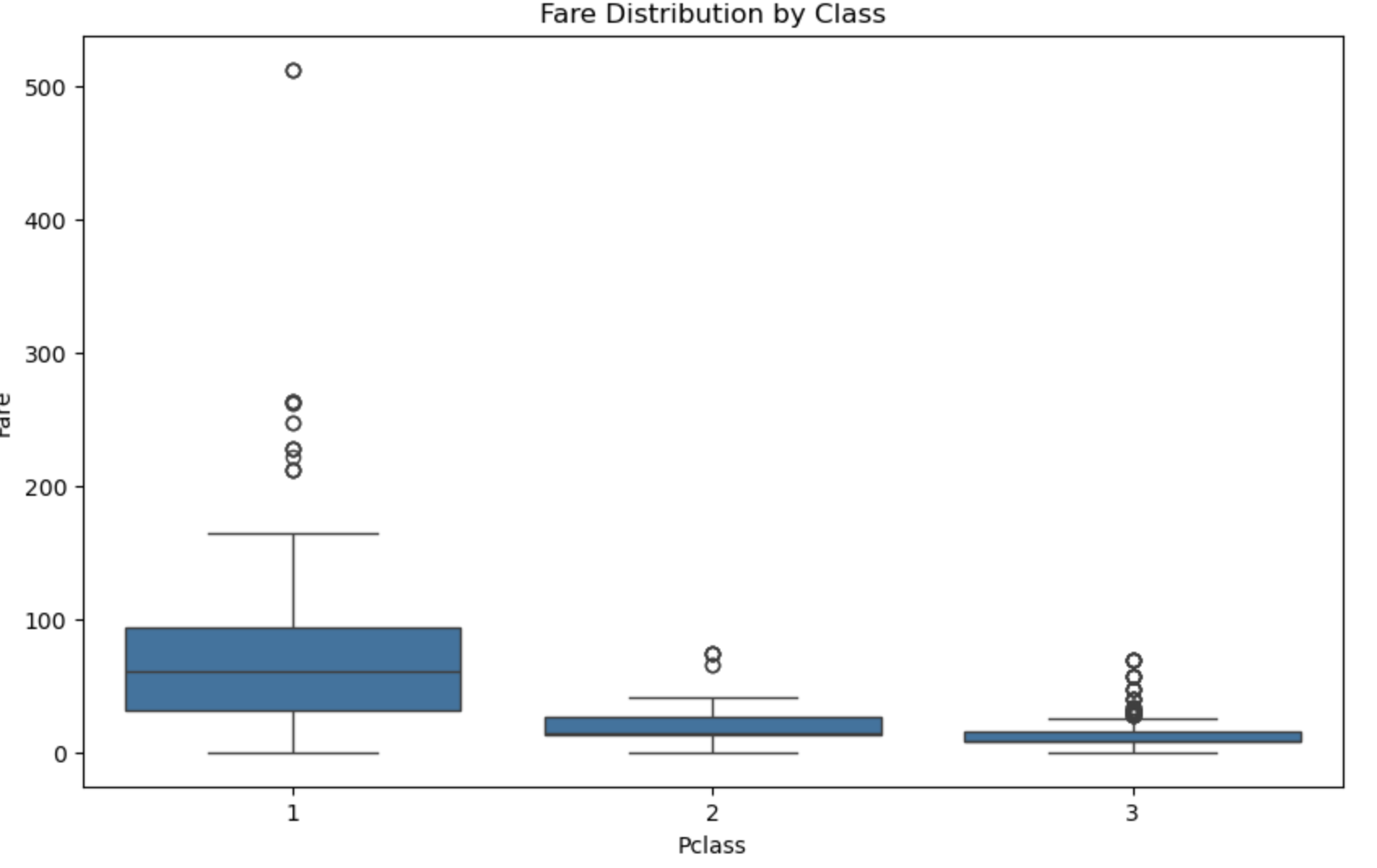
图9: 不同舱位的票价分布
模型训练代码
# 特征和目标值
X = df.drop('Survived', axis=1)
y = df['Survived']
# 数据拆分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 模型训练与预测
model = RandomForestClassifier(n_estimators=200, max_depth=10, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
研究结果
基于我们的分析,我们得出以下主要发现:
- 性别是影响生存率的最重要因素,女性的生存率显著高于男性
- 高级舱位(一等舱)的乘客生存率明显高于低级舱位
- 家庭规模对生存率有影响,中等大小的家庭(3-4人)生存率较高
- 年龄也是一个重要因素,儿童的生存率相对较高
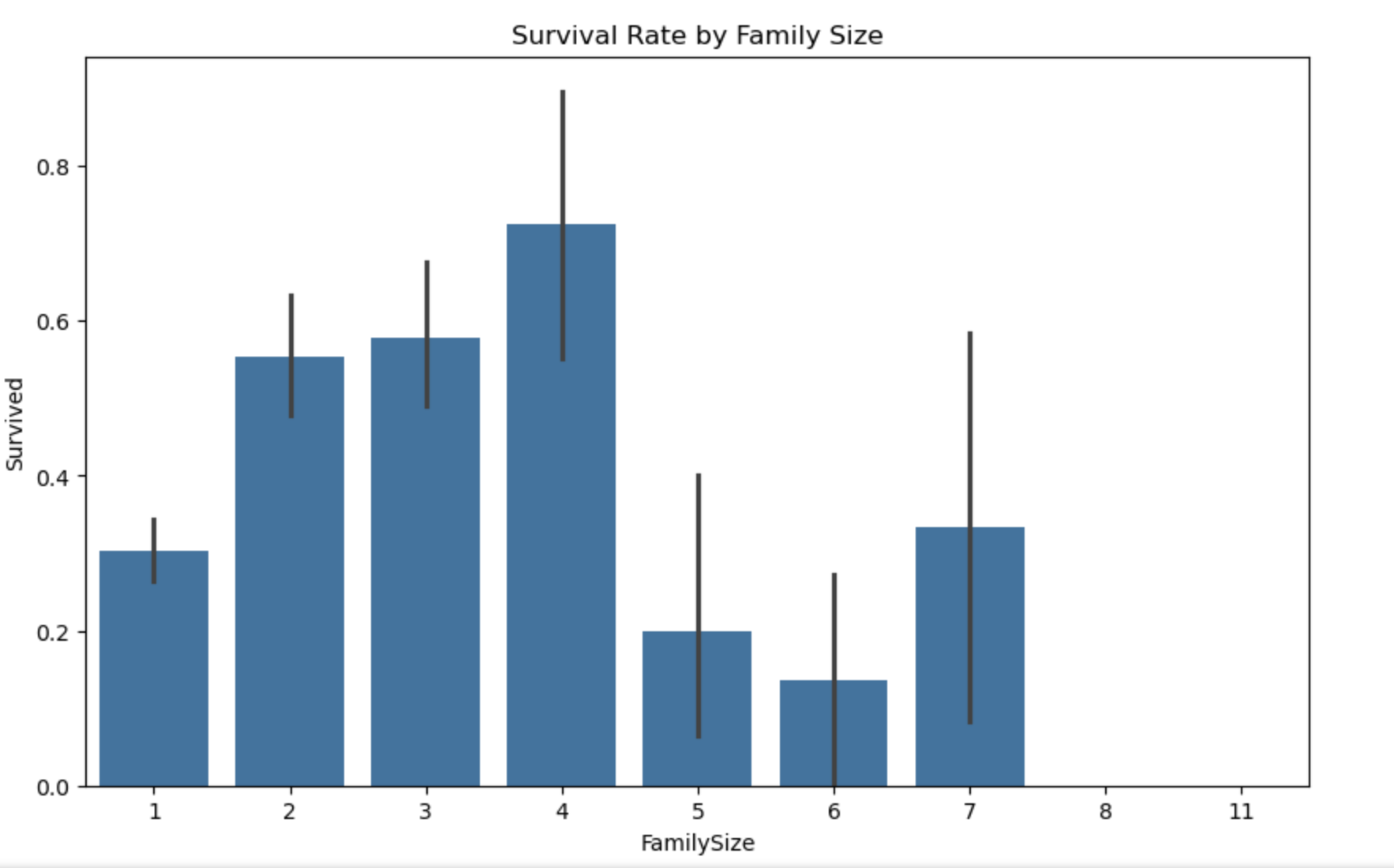
图10: 家庭规模与生存率的关系
模型评估代码
# 评估
test_acc = accuracy_score(y_test, y_pred)
print(f'Test Accuracy: {test_acc:.2%}')
print(classification_report(y_test, y_pred))
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))
# 数据可视化 - 生存率与特征的关系
plt.figure(figsize=(12, 6))
sns.barplot(x='Pclass', y='Survived', data=df)
plt.title("Survival Rate by Class")
plt.savefig('survival_by_class.png', dpi=300)
plt.show()
plt.figure(figsize=(12, 6))
sns.histplot(df['Age'], bins=30, kde=True)
plt.title("Age Distribution")
plt.savefig('age_distribution.png', dpi=300)
plt.show()
plt.figure(figsize=(8, 6))
sns.countplot(x='Survived', hue='Sex', data=df)
plt.title("Survival Distribution by Gender")
plt.savefig('survival_by_gender.png', dpi=300)
plt.show()
plt.figure(figsize=(10, 6))
sns.boxplot(x='Pclass', y='Fare', data=df)
plt.title("Fare Distribution by Class")
plt.savefig('fare_by_class.png', dpi=300)
plt.show()
plt.figure(figsize=(10, 6))
sns.barplot(x='FamilySize', y='Survived', data=df)
plt.title("Survival Rate by Family Size")
plt.savefig('family_size_survival.png', dpi=300)
plt.show()
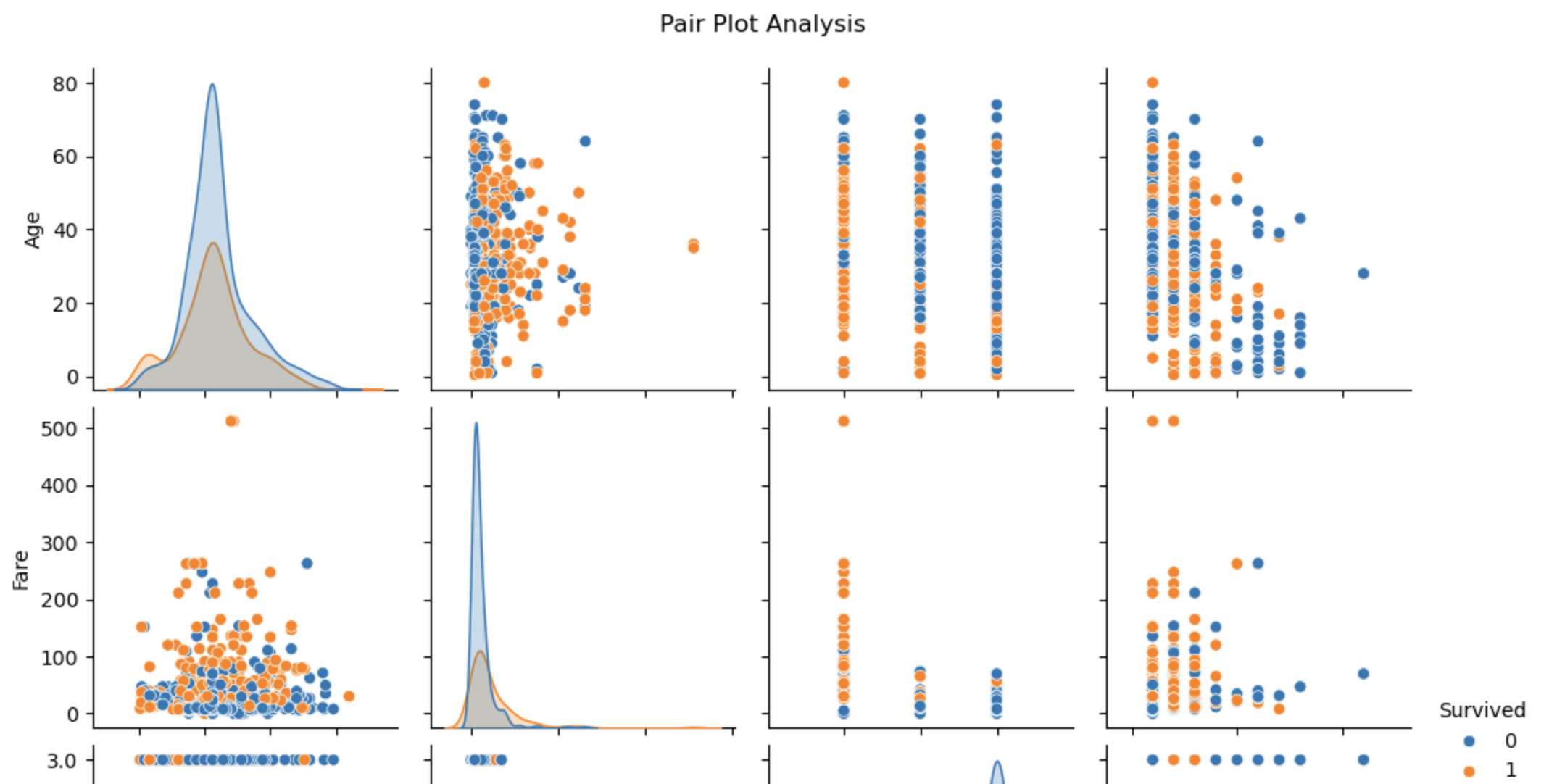
图11: 主要特征对关系图 1
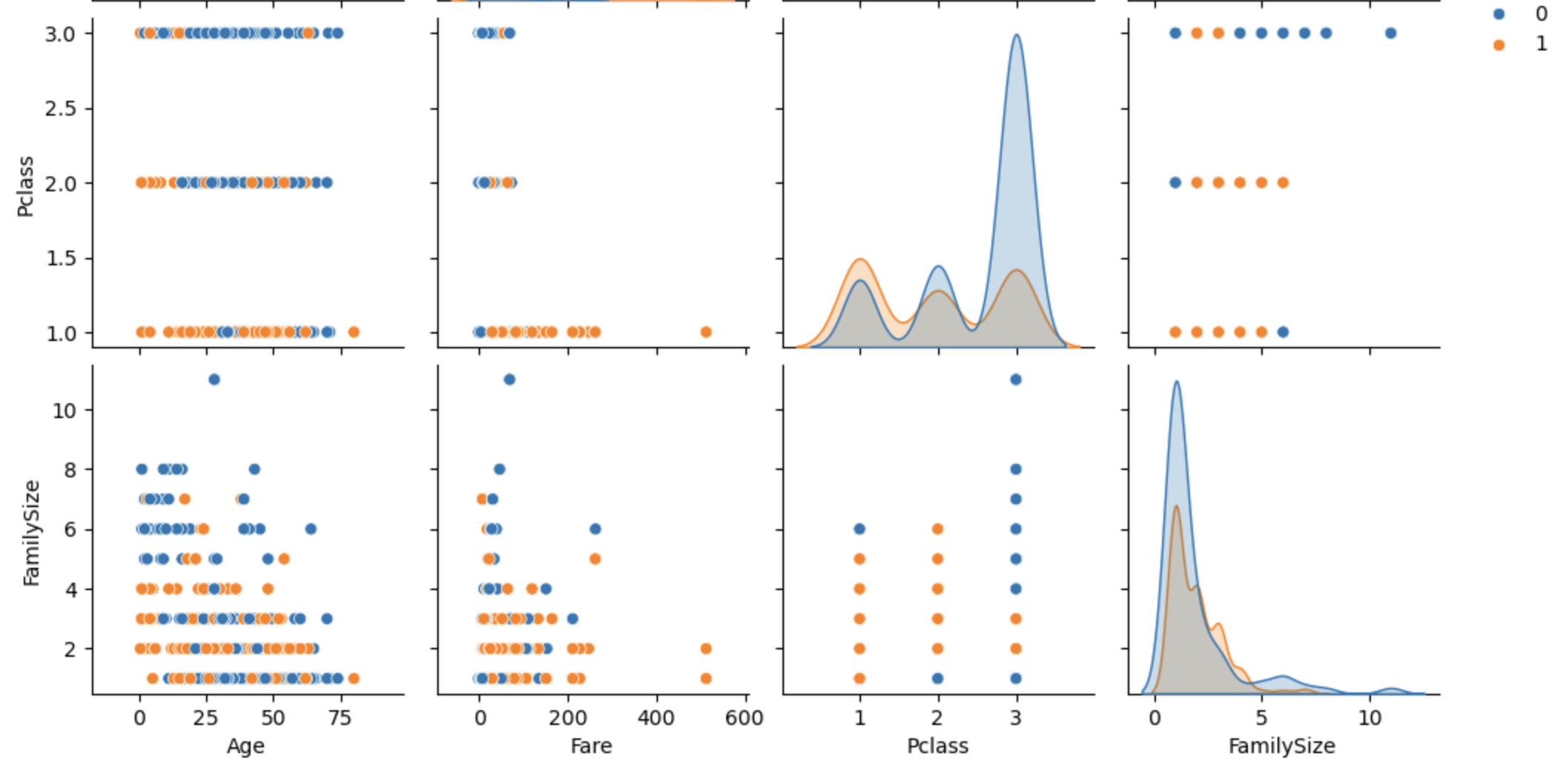
图11: 主要特征对关系图 2
plt.figure(figsize=(10, 6))
sns.pairplot(df[['Survived', 'Age', 'Fare', 'Pclass', 'FamilySize']], hue='Survived')
plt.suptitle("Pair Plot Analysis", y=1.02)
plt.savefig('pairplot.png', dpi=300)
plt.show()
MySQL数据分析
除了使用Python进行数据分析外,我们还使用MySQL进行了数据处理和分析。以下是MySQL分析的主要步骤和结果:
数据导入与表结构
首先,我们创建了一个MySQL数据库并导入泰坦尼克号数据集:
CREATE TABLE titanic (
PassengerId INT PRIMARY KEY,
Survived TINYINT,
Pclass TINYINT,
Name VARCHAR(255),
Sex VARCHAR(10),
Age FLOAT,
SibSp TINYINT,
Parch TINYINT,
Ticket VARCHAR(100),
Fare FLOAT,
Cabin VARCHAR(100),
Embarked VARCHAR(10)
);
-- 数据导入
LOAD DATA INFILE '/path/to/titanic.csv'
INTO TABLE titanic
FIELDS TERMINATED BY ','
IGNORE 1 ROWS;
数据清洗与预处理
使用SQL语句进行数据清洗和特征工程:
-- 删除不必要的列
ALTER TABLE titanic
DROP COLUMN Name,
DROP COLUMN Ticket,
DROP COLUMN Cabin;
-- 填充缺失值
UPDATE titanic
SET Age = (SELECT AVG(Age) FROM (SELECT * FROM titanic) AS t WHERE Age IS NOT NULL)
WHERE Age IS NULL;
UPDATE titanic
SET Embarked = 'S'
WHERE Embarked IS NULL OR Embarked = '';
UPDATE titanic
SET Fare = (SELECT AVG(Fare) FROM (SELECT * FROM titanic) AS t WHERE Fare IS NOT NULL)
WHERE Fare IS NULL;
-- 性别编码
ALTER TABLE titanic ADD COLUMN Sex_Encoded TINYINT;
UPDATE titanic SET Sex_Encoded = CASE WHEN Sex = 'male' THEN 0 ELSE 1 END;
-- 创建家庭规模特征
ALTER TABLE titanic ADD COLUMN FamilySize TINYINT;
UPDATE titanic SET FamilySize = SibSp + Parch + 1;
SQL分析查询
使用SQL查询分析关键模式:
-- 不同舱位的生存率
SELECT Pclass,
COUNT(*) AS Total,
SUM(Survived) AS Survived,
SUM(Survived)/COUNT(*) AS SurvivalRate
FROM titanic
GROUP BY Pclass
ORDER BY Pclass;

图12: MySQL分析 - 不同舱位的生存率
-- 不同性别的生存率
SELECT Sex,
COUNT(*) AS Total,
SUM(Survived) AS Survived,
SUM(Survived)/COUNT(*) AS SurvivalRate
FROM titanic
GROUP BY Sex;

图13: MySQL分析 - 不同性别的生存率
-- 家庭规模与生存率关系
SELECT FamilySize,
COUNT(*) AS Total,
SUM(Survived) AS Survived,
SUM(Survived)/COUNT(*) AS SurvivalRate
FROM titanic
GROUP BY FamilySize
ORDER BY FamilySize;
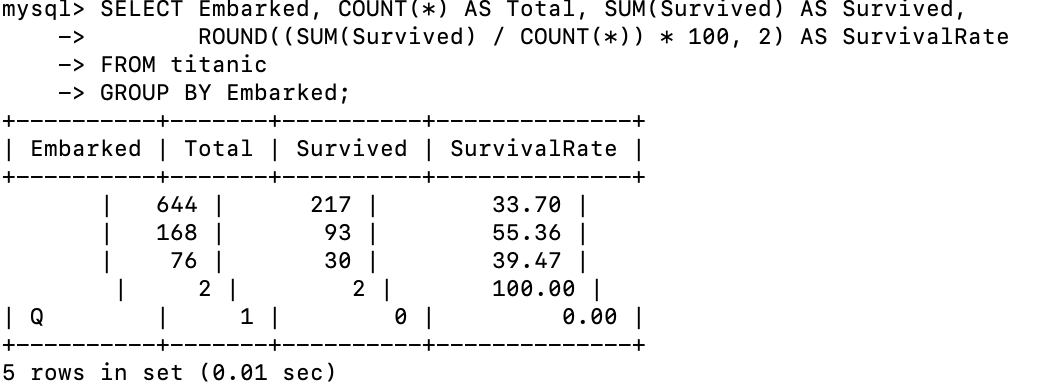
图14: MySQL分析 - 家庭规模与生存率关系
-- 年龄段与生存率关系
SELECT
CASE
WHEN Age < 10 THEN '0-9'
WHEN Age < 20 THEN '10-19'
WHEN Age < 30 THEN '20-29'
WHEN Age < 40 THEN '30-39'
WHEN Age < 50 THEN '40-49'
WHEN Age < 60 THEN '50-59'
ELSE '60+'
END AS AgeGroup,
COUNT(*) AS Total,
SUM(Survived) AS Survived,
SUM(Survived)/COUNT(*) AS SurvivalRate
FROM titanic
GROUP BY AgeGroup
ORDER BY AgeGroup;
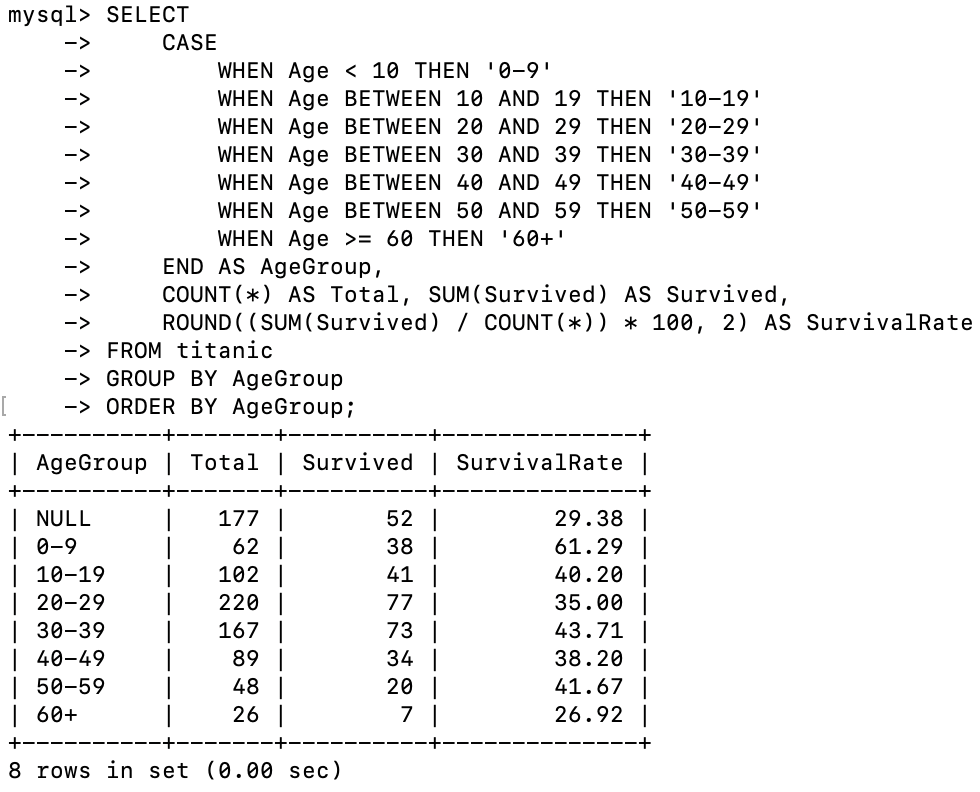
图15: MySQL分析 - 年龄段与生存率关系
Tableau数据可视化
我们使用Tableau创建了交互式仪表板,以便更直观地探索泰坦尼克号数据集中的模式和关系:
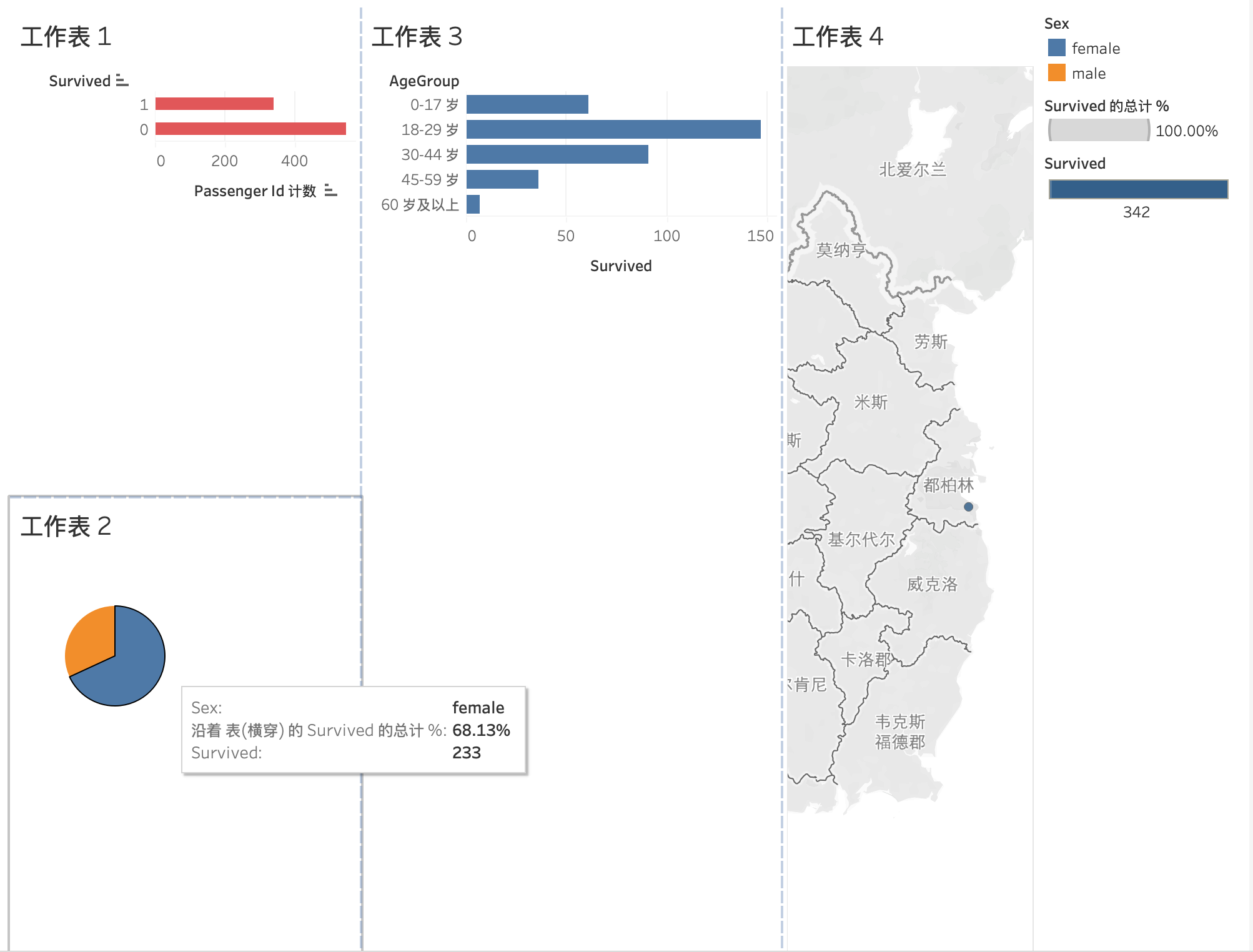
图16: Tableau交互式仪表板
Tableau可视化亮点
图17: Tableau - 生存因素综合分析
图18: Tableau - 登船港口与生存率关系
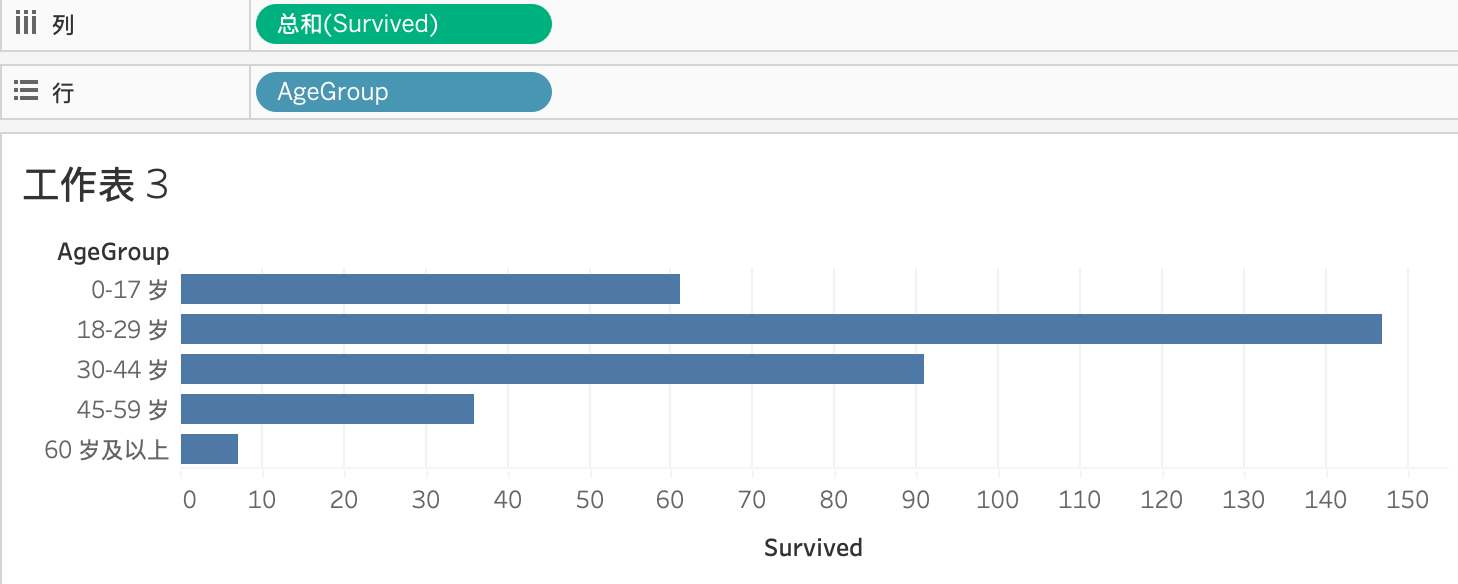
图19: Tableau - 年龄段分析

图20: Tableau - 票价与生存率关系

图19: Tableau - 年龄段分析
通过Tableau的交互式可视化,我们可以更灵活地探索数据,发现不同变量之间的关系,并以更直观的方式呈现分析结果。用户可以通过筛选、钻取等操作,从不同角度查看数据,获得更深入的见解。
结论
通过本项目的多维度分析(Python、MySQL和Tableau),我们可以得出以下结论:
泰坦尼克号灾难中的生存模式显示出明显的社会经济和性别偏向。一等舱乘客和女性的生存率显著高于其他群体,这反映了"妇女和儿童优先"的救生原则以及社会阶层对生存机会的影响。
我们的分析方法各有优势:Python提供了强大的机器学习能力,MySQL展示了结构化查询的效率,而Tableau则提供了直观的交互式可视化。这种多工具方法使我们能够从不同角度验证发现,增强了结论的可靠性。
随机森林模型能够以较高的准确率预测乘客的生存情况,这表明这些模式是稳定且可预测的。通过这个项目,我们不仅展示了数据分析的技术应用,也揭示了这场历史性灾难中蕴含的社会学意义。